
Mar 26, 2026
Pierre-Carl Langlais & Yannick Detrois
Two researchers, one shared frustration, several weekends.
We were generating training data for tool calling at scale. Dense models, fine-tuned on our own cluster. It should have worked. Instead, 30% of our tool call outputs were coming back with broken JSON that couldn't be parsed. Another chunk was producing what we started calling "tortured reasoning": the model technically following steps but failing to actually solve the problem, especially on multi-step sequences. We were throwing away most of what we generated just to get something usable.
The obvious move was MoE models. Better cost-to-quality ratio for inference-heavy synthetic pipelines, stronger capability ceiling. The problem: MoE models are a nightmare to fine-tune outside of big labs. Standard libraries barely support them. LoRA is mostly experimental. The most viable path we found was TorchTitan, a pretraining framework that takes a full day to set up correctly.
So we tried a different approach. We took our dataset (9,415 function calling examples, 30 million tokens) and ran it through every managed fine-tuning platform worth testing: Nebius Token Factory, Together AI, and Tinker. Same hyperparameters, four model configurations from Qwen3 8B to GPT-OSS 120B.
From dense models to MoE
Our existing setup was dense models from the Qwen 3 series, trained with trl on Jean Zay. Moving from conversational pipelines to specialized agentic models - working iteratively with structured data, custom ontologies, and complex tool sequences - exposed the limits of that setup fast.
MoE models were the obvious next step. Over the past year, they've offered a better cost-to-quality trade-off for inference-heavy pipelines, where throughput matters more than memory footprint. The problem: they're notoriously hard to fine-tune outside of big labs. Standard libraries barely support them. LoRA is mostly experimental. The training process is data-hungry since each expert sees only a fraction of the total tokens. The most viable path we found was TorchTitan, a pretraining framework that takes a full day to set up correctly.
The best dense base models below 12B (Qwen 3, Gemma 3) are now more than nine months old. Llama 3 is still widely used despite being nearly two years old. Managed fine-tuning platforms sidestep this entirely: the underlying architecture, MoE or dense, makes no difference to the user. Parallelism, sharding, checkpointing - all handled by the platform.
What we tested
We evaluated three platforms - Nebius Token Factory, Together AI, and Tinker - on a deliberately demanding benchmark. We also looked at Prime Intellect, still in private beta and with limited model overlap, so it is not included in the full comparison.
We assessed each platform along the following dimensions: general service offering beyond strict fine-tuning (including integrated pipelines for synthetic generation and LLM-as-a-judge evaluation), quality of infrastructure and UI, cost-to-performance, model availability, and deployment of fine-tuned models for inference.
Training data
Our dataset comprises 9,415 unique examples built around Wikipedia seeds, standardized features (environment type, tool call pattern, language, outcome), a short reasoning sequence, a synthetic natural-language query, a synthetic list of available tools in JSON format with carefully designed distractors, and the final correct tool call. Total: 30 million tokens. The dataset was generated by several frontier models including DeepSeek V3.2 and Minimax, with additional internal curation.
The four experiments
We ran four experiments across two architecture families:
1.1: Medium MoE: Qwen3 30B instruct (3B active parameters)
1.2: Large MoE: GPT-OSS 120B
2.1: Small dense: Qwen3 8B
2.2: Medium dense: Llama 3 70B
Core parameters were held constant across all runs: 16,384 token context length, batch size 8, three epochs, uniform learning rate. LoRA rank 8 for LoRA experiments.
One important caveat: for Run 1.1, Nebius Token Factory is the only provider offering full fine-tuning. Tinker and Together AI only support LoRA for this model, so performance cannot be fairly compared across providers for this specific run. The other experiments all use LoRA (Tinker does not support full fine-tuning at all).
Results
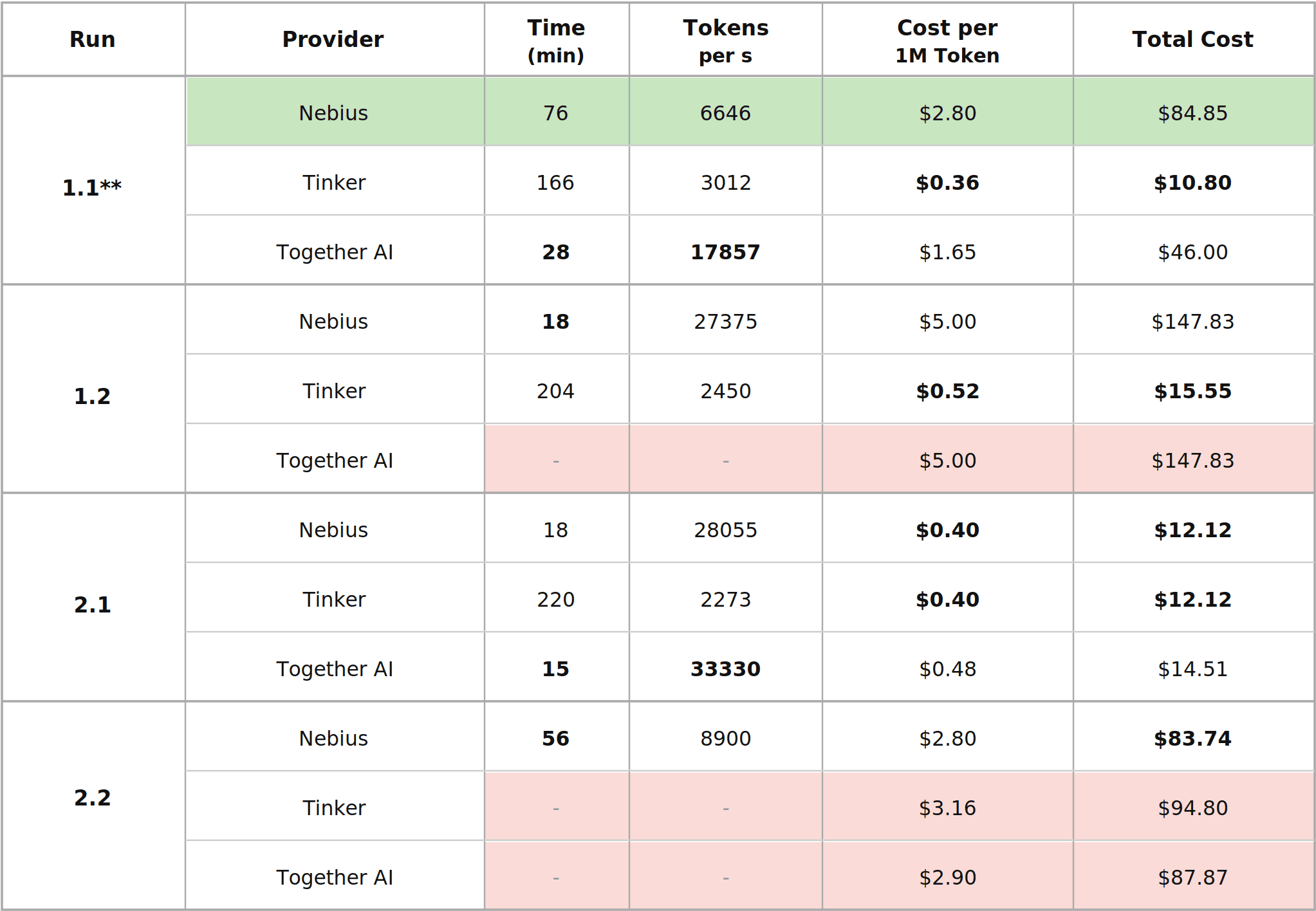
Speed: Together AI and Nebius are in the same range, both considerably faster than Tinker. Together AI was faster on Run 2.1 (15 vs 18 minutes). On Run 1.1, Together AI completed in 28 minutes versus 76 for Nebius - but this reflects a full fine-tuning vs LoRA difference, not raw platform speed, so the comparison doesn't hold. Together AI did not complete Run 1.2. On the runs where the comparison is direct, the two platforms are broadly equivalent.
Cost: Two clear tiers. Tinker is substantially cheaper across the board. Nebius and Together AI sit in a comparable higher tier, with Nebius generally slightly less expensive.
Platform-by-platform assessment
Tinker
Tinker provides a low-level training abstraction: users write essentially the same code they would use for local training, and the platform manages distributed execution across GPUs. For researchers who need custom implementations and want to avoid operational complexity, this is useful.
The practical limitations are real though. No cost or time estimation in the interface, and costs for past runs are unclear even retroactively. No built-in support for Weights & Biases or HuggingFace model uploads. Only LoRA is supported. No inference or deployment capability. Model availability is more limited than the other platforms. Out-of-the-box throughput is slow, as optimization is left entirely to the user.
The main advantage is cost: Tinker is considerably cheaper in most configurations.
Best for: Teams with strong infrastructure expertise who primarily need cheap distributed compute and already have their own evaluation and deployment tooling.
Together AI
Together AI offers both a programmable API and a graphical interface. Users can browse models, test them in a playground, and access inference through both serverless and dedicated endpoints. Fine-tuning jobs can be cloned from previous runs. The interface shows expected cost before launch. Weights & Biases integration is built in.
The model catalog is the broadest of the three platforms, covering LoRA and full fine-tuning for both dense and MoE models, plus SFT and RL. That said, not every method is available for every model - availability is model-dependent and the documentation doesn't always reflect what's actually accessible. Serverless inference is billed per token but restricted to certain models. Those without serverless support require dedicated endpoints billed by runtime. Batch inference is also rigid on input format: the dataset needs to be restructured to match each model's template, which adds friction when iterating fast.
Best for: Teams that want a balanced platform with the broadest model selection, good speed, and a usable interface, and can tolerate some friction around inference deployment.
Nebius Token Factory
Nebius offers both code and no-code paths for fine-tuning and inference, supports LoRA and full fine-tuning, SFT and RL, with automatic handling of parallelism, scheduling, and checkpointing. Training speed is on par with the fastest platforms. The interface shows predicted costs and estimated completion time. Weights & Biases and HuggingFace integrations are built in.
Two features stood out in our workflow. The Data Lab lets you inspect and validate input and output datasets directly on the platform. For an iterative function calling pipeline, this meant we could examine training data and model outputs without constantly exporting files. The one-click serverless inference deployment of fine-tuned LoRA models was the most direct path to evaluating model output right after training. Input format is also flexible for both training and inference, accepting conversational, instruction, or plain text without requiring dataset restructuring before each run.
We also ran into friction worth documenting. Cost estimation during runs was unreliable at times, staying flat for most of the run then jumping sharply near the end. The chat assistant in the interface didn't consistently return responses during our testing period. A JSONL upload failed with an "incorrect JSON" error that disappeared after simply reshuffling the file. These are minor individually, but they compound when you're running multiple iterations per day.
Best for: Teams running iterative fine-tuning and evaluation loops who need the full lifecycle (data inspection, training, inference, evaluation) under one roof, and value deployment simplicity over lowest possible cost.
Takeaways
Training speed and cost have mostly stopped being the story. The three platforms are close enough on both that they're no longer the deciding factor.
After a 76-minute training run, the question we kept asking wasn't about distributed training configuration. It was: how quickly can we actually look at what the model learned? Can we inspect the training data without exporting it? Can we run inference on the fine-tuned model in the next five minutes, or does the dataset need to be restructured and an endpoint spun up first? Too often, the time saved by a faster run was spent dealing with data handling the platform hadn't thought through.
On those questions, the three platforms land in very different places. Tinker gives you maximum control and minimum cost, but every workflow decision sits with you - solid compute if your team already has its own tooling. Together AI has the broadest model catalog and good speed, but inference deployment adds steps that compound when you're running multiple iterations a day. Nebius was the only platform where the full loop (data inspection, training, deployment, inference) held together without constant context-switching between tools.
For teams running iterative post-training at any scale, the real cost is the hour lost per cycle moving data in and out of platforms that weren't designed to work together.
This benchmark grew out of shared frustration with fine-tuning infrastructure and a free weekend.
CONTACT US


