
Nov 10, 2025
SYNTH: the new data frontier
Since GPT-3, language models have been mostly trained on large collections of web archives. During the past year, Frontier AI labs have reconsidered this approach as they move toward reasoning and agentic models requiring a large amount of generally unwritten traces for thoughts, actions or tool calls.
We release SYNTH, a fully generalist synthetic dataset, that represents a fundamental break from the common pre-training paradigm: what if we trained for reasoning and focused on the assimilation of knowledge and skill that matters? Classic benchmarks are already operating under this assumption: MMLU, gsm8k, MATH, are all ultimately based on collections of high school exercises.
SYNTH stems from 50,000 vital Wikipedia articles, expanded into a wide collection of problems and resolution paths, from math exercises to creative writing, information extraction or sourced synthesis. While similar traces might be available in standard pretraining datasets, they are isolated and noisy which ultimately slows down the learning process and delays the acquisition of valuable reasoning skills.
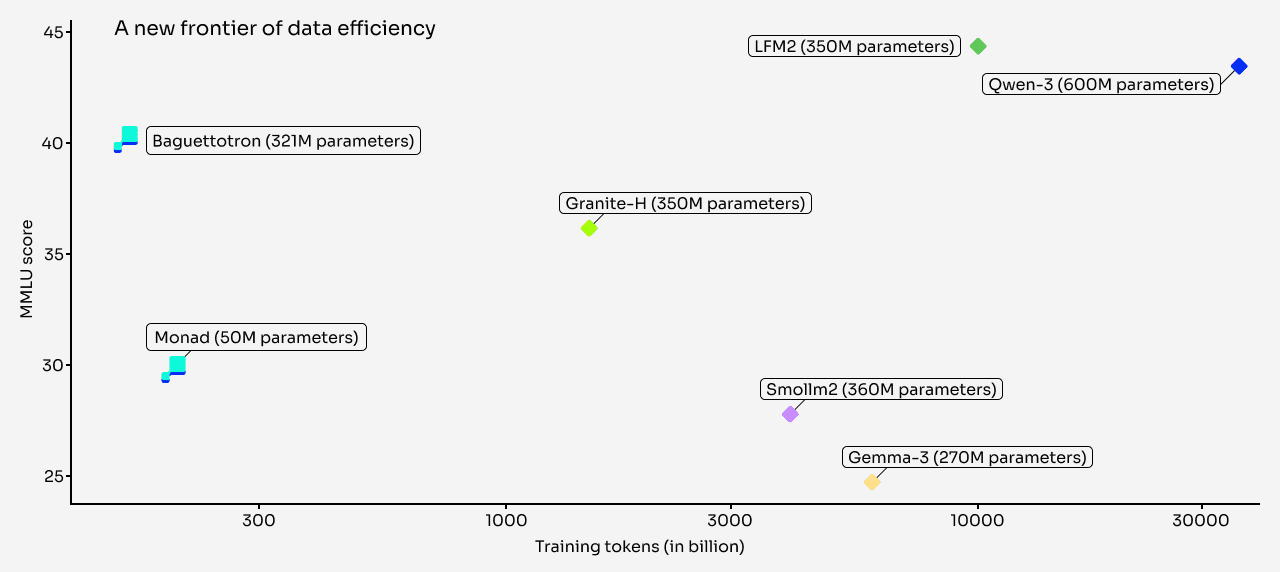
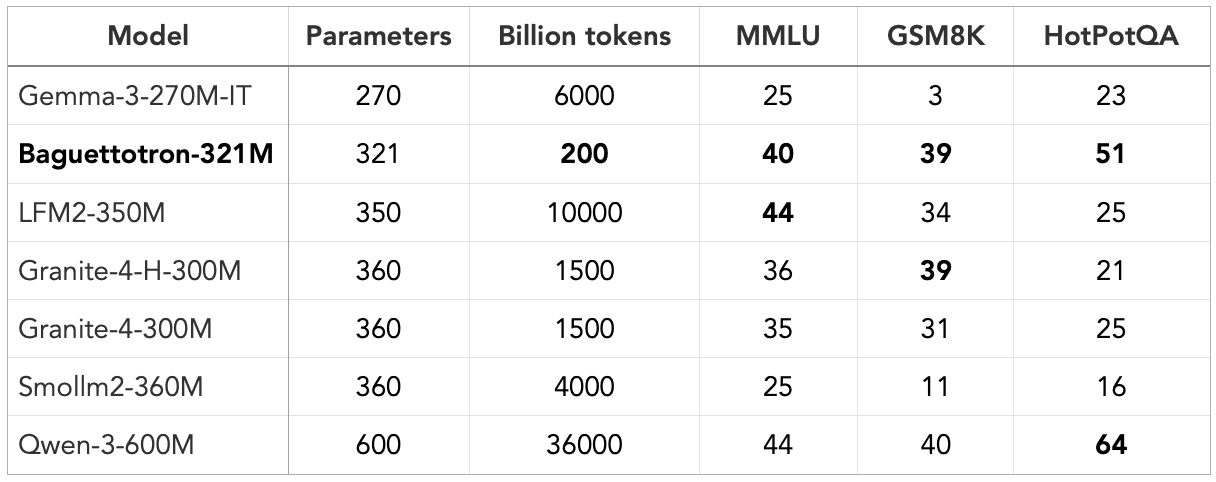
We trained two SOTA small reasoners - Baguettotron and Monad - on less than 200 billion tokens from SYNTH, that is between 10 and 50 less data than models with similar or lower performance. Baguettotron is currently the best in class across major industry benchmarks (MMLU, gsm8k, HotPotQA). 56M parameters Monad is a contender for the smallest viable model, as it attains non-random performance on the same benchmark suite.
With this release, we advance several claims:
With reasoning-focused synthetic data, models can attain SOTA results with low compute costs: our final training runs represent less than 1000 H100 hours. The overall project (synth generation and experiments included) amounted to 20,000 h100 hours, all thanks to a Genci/Jean Zay compute plan.
Expanded coverage of tasks and data sources solve most of the problems (“model collapse”) associated with synthetic generation: SYNTH is not English-only nor single-turn only. It includes a sizable share of content in other European languages and for conversational use cases.
Small open high quality sources are increasingly more valuable than large data collections of questionable provenance. Combination of seed under open licenses and model output without restrictions solves data releasability under most jurisdictions.
Designing an open synthetic playground
SYNTH combines a collection of several synthetic pipelines. What this means in practice is that the synthetic data was not simply generated by prompting a large model, but instead integrating smaller fine-tuned models into more or less complex workflows. This move was motivated by four factors:
Inference economics. While synthetic training is more data efficient it still requires the generation of tens of billion tokens.
Grounding. We constantly used Wikipedia articles as seed, ensuring every factual assertion in generated data could be traced back to verifiable encyclopedic content.
Diversity. We implement randomized constraints at different stages of synthetic pipelines, either during query or answer generations. We found they helped present model collapse and reinforce the resiliency of the model to unplanned content.
Verification. Some pipelines allowed for formalized checks or LLM-as-a-judge curation. We generally found increased performance from dropping bad/tortured reasoning traces even at the expense of data volumes.
In effect, this approach means that the overall system is better than its individual components. Critically, the models used for synthetic generation have access to information the final training model won’t see directly: this can include for instance, the final numeric answer from formalized math problems, encyclopedic information, past conversation exchanges. From this point on, they generate reasoning traces and answers by simulating to not know the answer already. This process of backreasoning (or traceback) is a fundamental building block of small reasoner training: models are never faced with straight answers but with a continuous process of answer building.
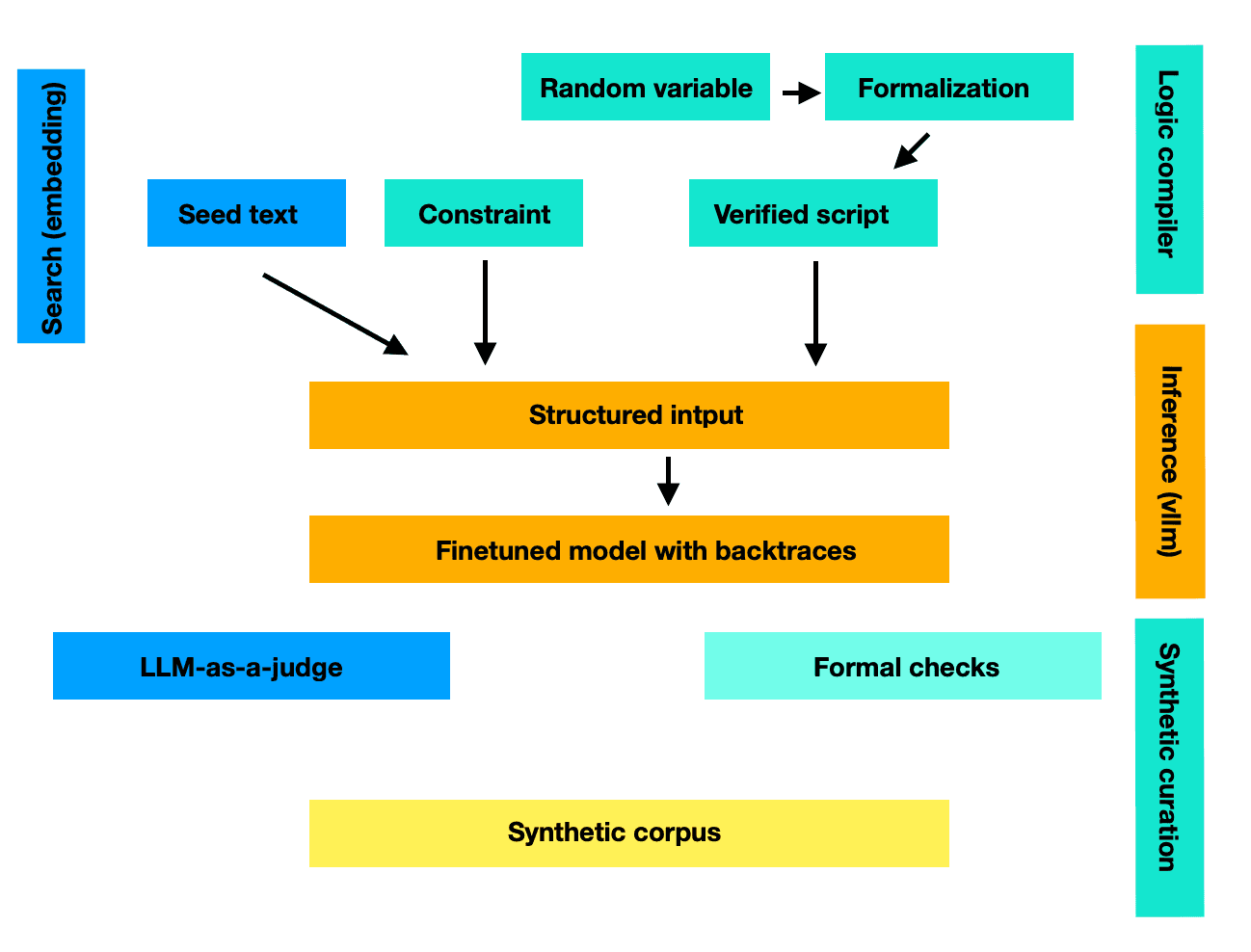
Overview of SYNTH synthetic pipelines.
To operationalize this program, we took significant inspiration from LLM applications. The core building blocks of each pipelines include:
Finetuned models designed to take structured input and generate structured output, rather than custom prompting.
Orchestration of inference processes at scale, usually involving several steps/inputs.
Scaling search and retrieval for seeds using embedding models.
We expect this connection between LLM training and deployment to deepen even further as we’ll expand SYNTH to more agentic use cases.
SYNTH is structured around a “memory core”, the Wikipedia vital articles.. Throughout the past two decades, thousands of contributors selected a collection of core topics that every encyclopedia should have: it’s a concentric selection starting at level 1 (10 articles) up to level 5 (50,000 articles). SYNTH includes as its starting point all articles featured in level 5. It further expands on this selection by increasing coverage of more specialized domains (physics, chemistry, law…) through targeted expansion of wikidata knowledge graphs. The usability of this resource was further enhanced by the Structured Wikipedia project from Wikimedia Enterprise: by parsing directly rendered Wikipedia articles in html, Structured Wikipedia fixes most of the formatting issues linked with the mediawiki syntax and provides a clean, section-based version of all Wikipedia pages.
From this initial core, SYNTH was built in a modular way by gradually incorporating a wider range of operationalized tasks and pipelines until it uncovered most of the expected use cases of small reasoning models:
Memorization/retrieval with queries back-translated from different knowledge databases (mostly Wikipedia vital articles) and expanded with embedding search.
Retrieval-Augmented Generation. Roughly the same process as the memorization pipeline except with more sources (up to 10) and the model getting access to the sources and focusing on grounding rather than remembrance.
Arithmetic problems. We gathered a collection of 3000 formalized exercises, mostly from the Kimina dataset and expanded it through random variation of initial variables.
Editing tasks. This encompasses a wide variety of text modifications, from translation to information extraction or correction. We let the synthetic model select the most fitting task depending on the submitted input.
Creative writing. We combined Wikipedia seed (for knowledge/environment background) with a set of random constraints, partly inspired by the French literary movement Oulipo. This typically includes lipograms (writing without using the letter ‘e’).
Multi-turn conversations. They were created from already generated single-turn interaction, drawing from all past exercises.
About 20% of SYNTH is multilingual with, for now, a focus on the leading European languages represented in Common Corpus: French, German, Spanish, Italian and Polish (as well as Dutch and Latin to a lesser extent). Conversely, we intently excluded code from SYNTH, considering this would have required many additional infrastructure developments significantly delaying this release.
SYNTH has been designed around a set of open standards for synthetic data established in collaboration with the AI Alliance. We implemented two critical requirements for synthetic data releasability and reusability:
Model attributions: this is now largely feasible since major open weight models (Qwen, DeepSeek, GPT-OSS) no longer implement restrictions on synthetic outputs.
Seed attribution: every text used in the synthetic pipeline has been attributed and, thanks to the availability of the original data under CC-By-SA, re-released.
We believe open synthetic environments have the potential to become more effective than closed environments. To progress further, synthetic pipelines now largely require expanded collaborations with specialized domains and industries as well as familiarity with large existing open and interoperable sources
The case for deep reasoners
We trained two reasoners on SYNTH - Baguettotron (321m parameters) and, to our knowledge, - the smallest viable language model to date, Monad with 56M parameters (less than half parameters than GPT-2). Along with being trained exclusively on a synthetic reasoning corpus, both models share an unusual design choice justified by controlled experiments on SYNTH: extreme depth. As shown in the model scheme below, Monad has 64 layers and Baguettotron 80 layers.
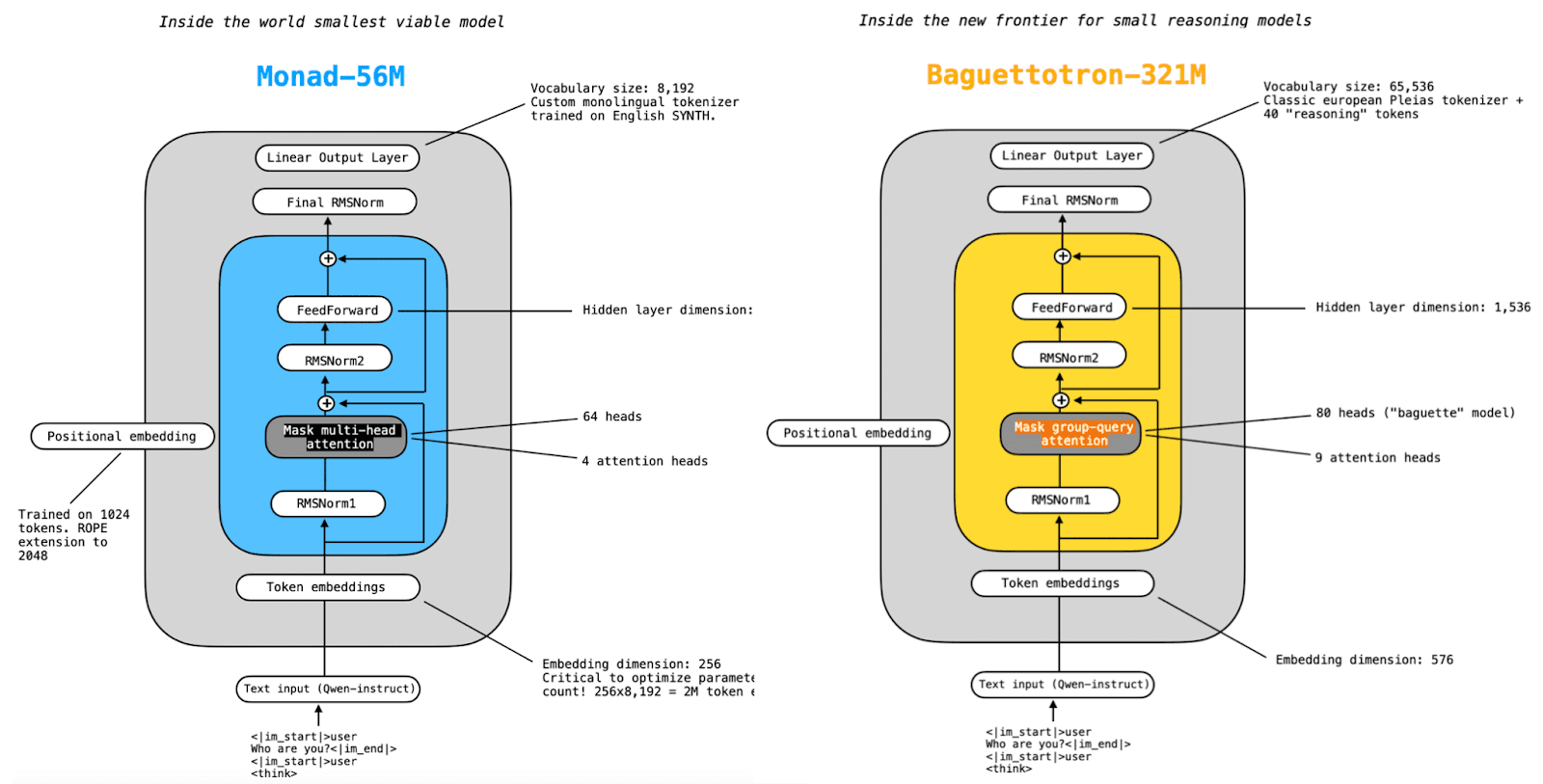
Internal structure of Monad and Baguettotron. Design inspired by Sebastian Raschka.
Monad and Baguettotron were trained on 16 h100 from Jean Zay using the Nanotron framework from HuggingFace. This setting allowed for fast experimentations and iteration, Monad being trained in less than six hours. While Baguettotron reuses the standard Pleias tokenizer optimized for European languages, Monad uses a custom tokenizer trained on the English segment of SYNTH: this was a critical measure to contain parameters space, bringing back token embeddings from 20M to less than 2M.
We evaluated the two models on three major industry benchmarks MMLU (general reasoning and memorization), math (gsm8k) and retrieval (HotPotQA), as well as custom generated synthetic benchmarks backtranslated from our Wikipedia set. The latter proved more convenient to assess memorization regardless of the potential disconnect between MMLU and our encyclopedic data sources. By the end of this training cycle, Baguettotron performance was best in class:
Consistently with the hypothesis of Physics of language models, training for reasoning tasks and patterns enabled “the early and consistent emergence of advanced skills”. Small models trained on webcrawl pretraining data only start to get non-random results after trillions of tokens, if at all. Whereas with Baguettotron, we were able to get consistent signals on MMLU during the first two hours of training (from step 9,000 onwards).
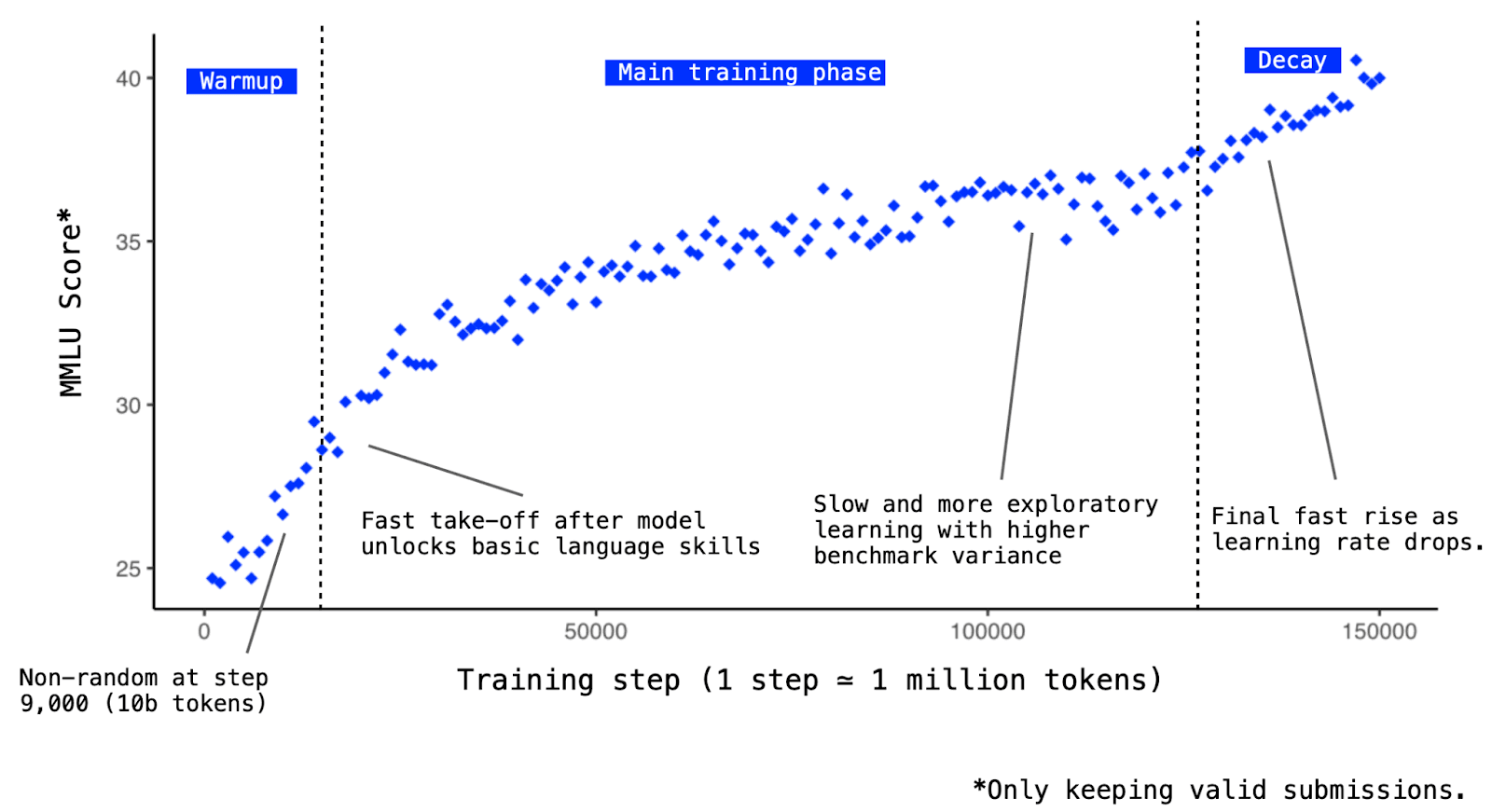
MMLU results of Baguettotron throughout training, showing very early reasoning signals.
This unique feature of SYNTH facilitated controlled experiments over model architectures beyond limited ablations. We empirically measured consistent improvements from stacking more layers. Our current hypothesis is that deeper architecture benefits more from dense reasoning data, as the model is more commonly exposed to string sequences requiring intensive computation or knowledge interconnection. And deep architectures also mitigate surface-level learning by adding more inertia to data assimilations.
Synthetic playground as context engineering
Working on SYNTH forced us to think differently about what "training data" means. We weren't collecting diverse internet text hoping the model would learn everything. We were intently engineering specific capabilities: semantic bridging between concepts, query expansion, multilingual harmonization, constraint-based reasoning. The synthetic pipeline creates shaped data. Data designed to instill particular transformations, particular ways of connecting information, particular reasoning patterns.
Full synthetic training will not (yet?) realistically build a "gpt-5 at home". Yet we believe it can already have a transformative impact around frontier models. The current majoritarian paradigm for deploying AI assumes a simple architecture: collect relevant information, dump it into a foundation model's context window, hope for the best. It does work, sort of. But it's also extraordinarily inefficient and prone to failure.
The real lesson we took from synthetic data efficiency isn't just "you can train smaller models" for a very small cost - it's "context preparation is as important as the model itself”. While designing the synthetic pipelines, we simulate a range of tasks and workflows actively deployed in production. This process culminates into an actual orchestration of smaller finetuned models, symbolic methods with hardcoded constraints and retrieval flows that achieves a higher degree of intelligence than its individual component.
What if instead of sending raw enterprise data directly to your generative models (open source or closed ones), it is first routed through a layer of engineering to shape the data in a way that:
Understands domain ontology and can semantically enrich queries
Harmonizes multilingual content into consistent representations
Generates synthetic variations that expose reasoning patterns
Enriches it with contextualised reasoning structures
Explores new relationships inside existing knowledge base, through retrieval, iterative search or (generated) data graphs.
Decomposes complex processes into integrated generative and symbolic workflows with sequential checks.
Assesses domain-specific performance through synthetic benchmarks.
This wouldn't replace foundation models, they'd prepare context that will make them work significantly better. Think of it as a pre-processing layer, but one that actually understands contexts rather than just applying rules.
What's Next
Over the coming months we'll be:
Publishing more details on the synthetic generation pipeline
Exploring domain-specific adaptations (legal, medical, technical documentation)
Implement controlled experiments on memorization and continual learning
Testing different architectural patterns for context preparation
Working with early partners on real-world deployments
With the support of:


CONTACT US


